構造化プログラミング
構造化プログラミングとは?
順次構造、選択構造、繰り返し構造のみを使って、呼び出し元プログラム→モジュール→サブモジュールという全体構造を作っていく。
プログラム上の指定の位置に移動するgoto文を排除することで、プログラム全体の見通しをよくするための考え方。
構造化プログラムの要素
- 順次構造…上から下に順番に処理を行う。
- 選択構造…条件によって行う処理を分岐する。主にif文。
- 繰り返し構造…ある条件になるまで同じ処理を行う。
- 前判定繰り返し型…条件判定を最初に行う。while型とも呼ぶ。
- 後判定繰り返し型…条件判定を最後に行う。do-while型とも呼ぶ。
データ構造
配列
リスト
キュー
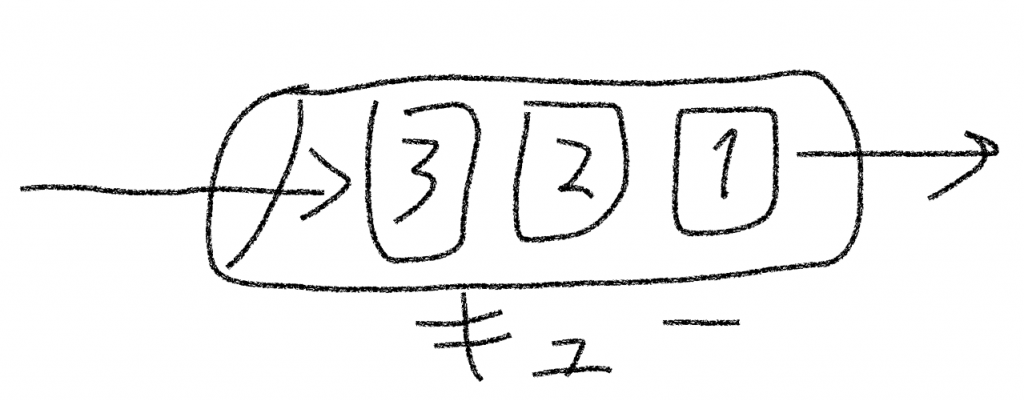
キューは待ち行列と呼ばれる。先入れ先出し方式(FIFO:First In First Out)の構造である。
入れた順番に取り出せる構造である。
順番待ちのように、追加された順番に処理を行いたいときに使用する。
スタック
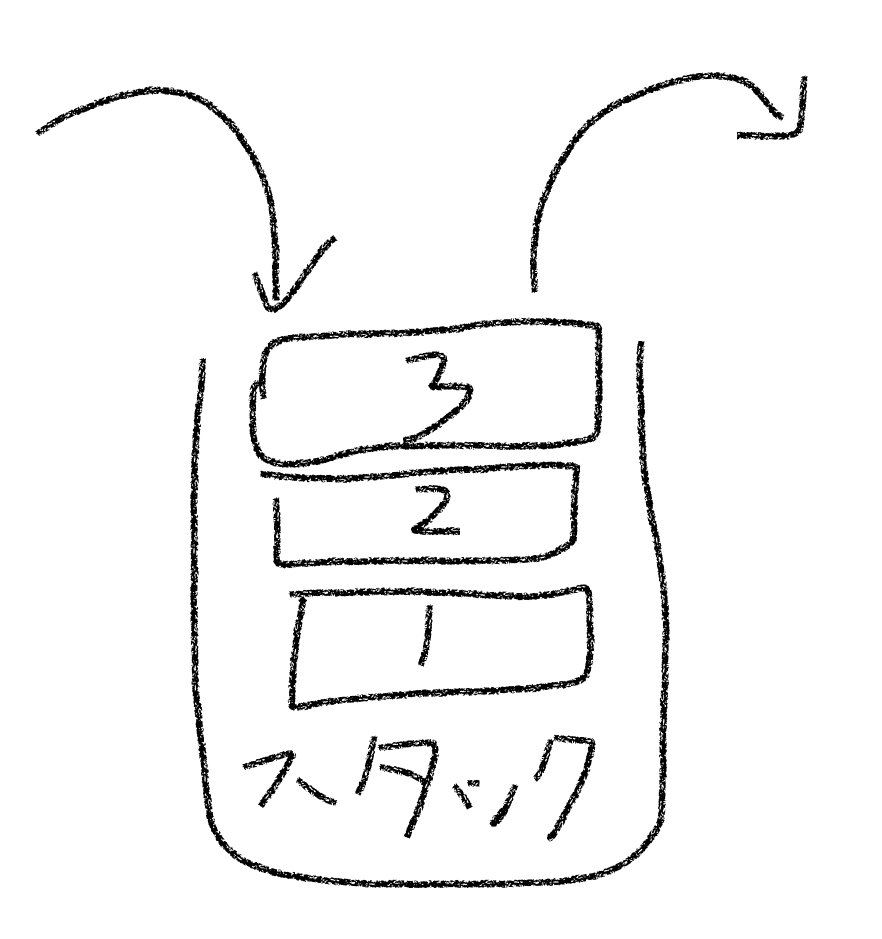
スタックはキューの逆で、先入れ後出し方式(LIFO:Last In First Out)の構造である。
最後に入れたものを最初に取り出す構造である。
ツリー構造(木構造)
データの階層構造を表すために使用される。データの探索や整列でも非常によく使用される。
例)ファイルシステム(ディレクトリ構造)、URLのドメイン名
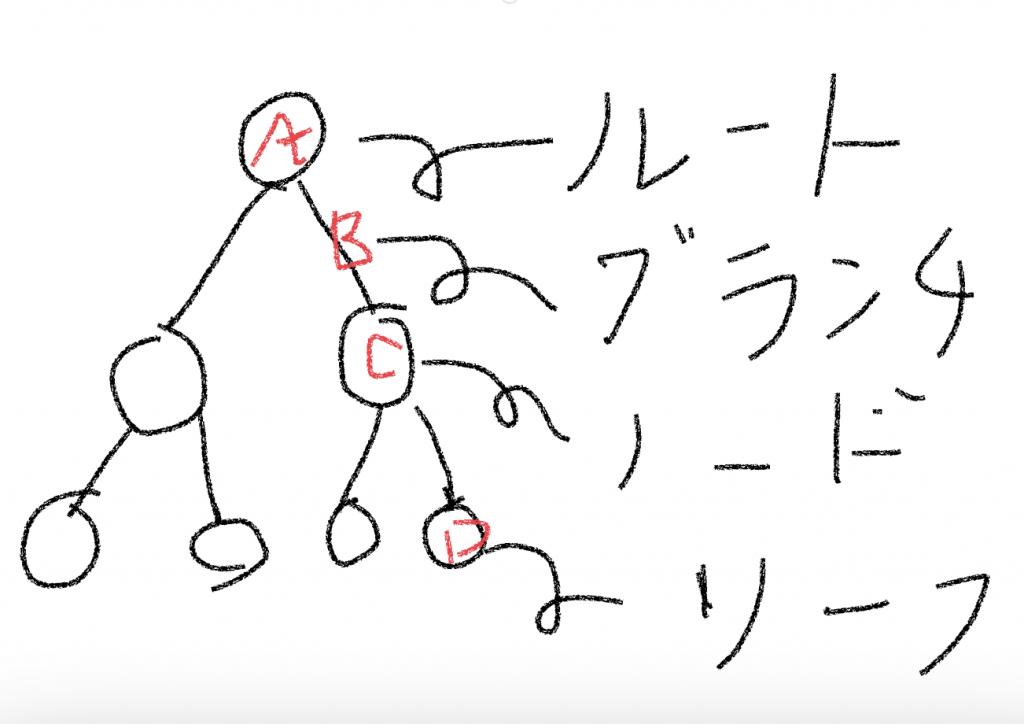
- ルート…木の一番上のノードのこと
- ブランチ…木から分岐してる枝のこと
- ノード…木から分岐した枝の先にある節のこと
- リーフ…木の一番下のノードのこと
完全2分木
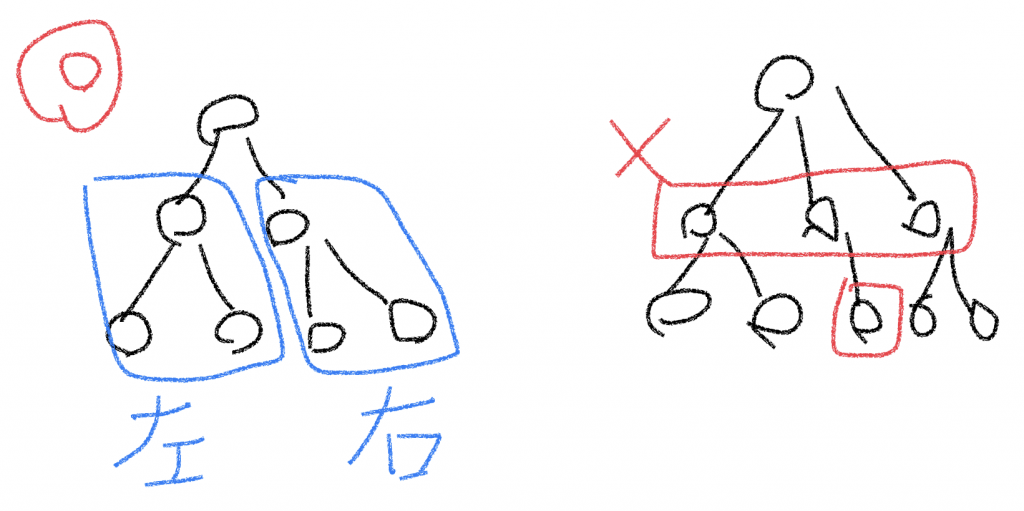
全ノードが2つの子を持ち、ルートから全てのリーフまでが同じ深さを持つツリーを完全2分木と呼ぶ。
ノードから分岐するブランチの左側を左部分木、右側を右部分木と呼ぶ。
2分木とは、ノードから分岐するブランチが2本以下のツリーのこと。
ノードから分岐するブランチが3本の場合は3分木になる。
2分探索木
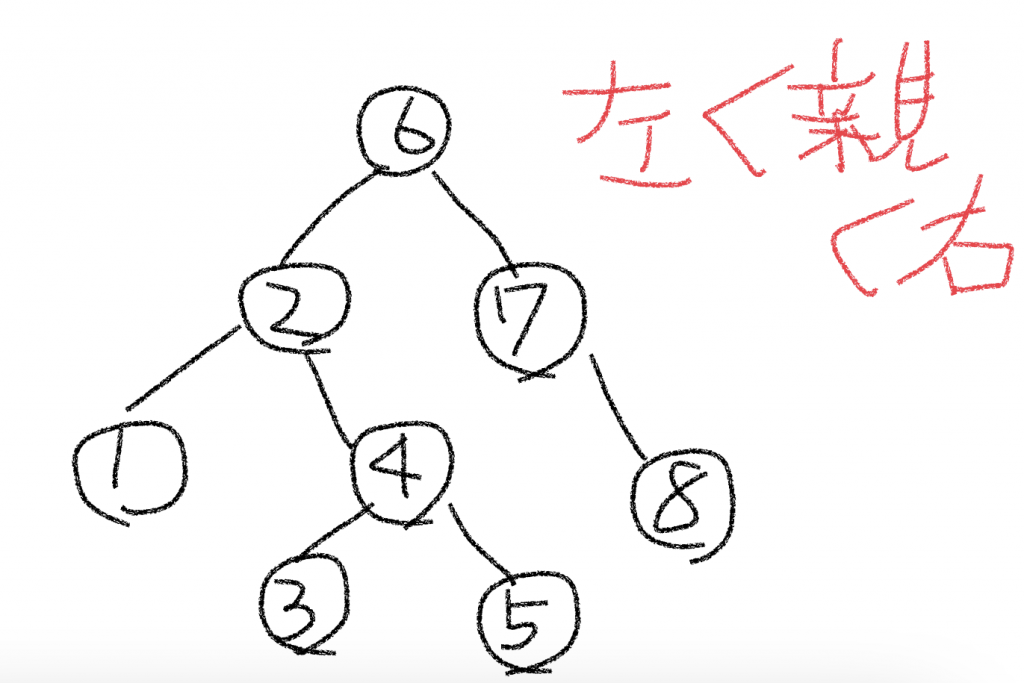
ノードの持つ値が常に左<親<右となるツリーを2分探索木と呼ぶ。常に左<親<右の関係にしておくことで、値の場所をすぐに調べることができるため、探索木と呼ばれる。
アルゴリズム
線形探索法
2分探索法
ハッシュ法
オブジェクト指向
is-a関係、has-a関係、part of関係
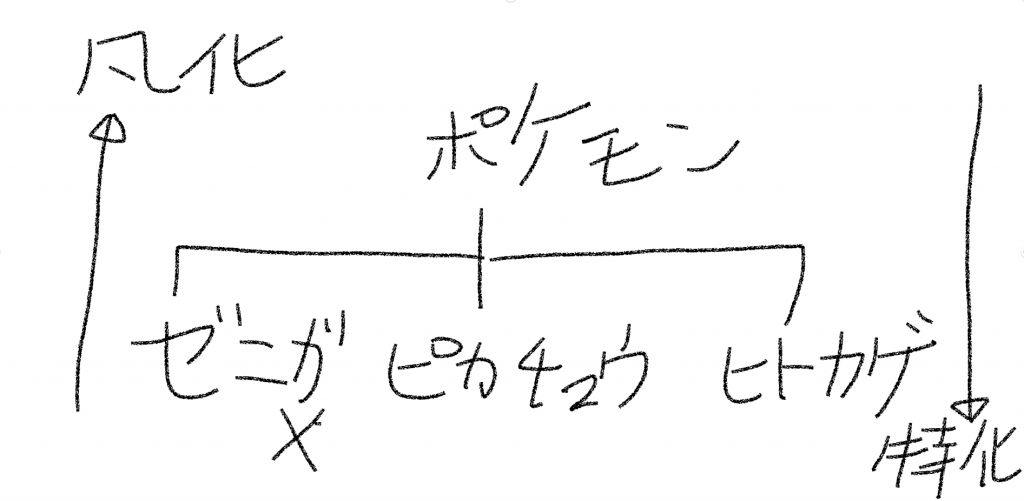
Class ゼニガメ extends ポケモン というクラス構成になる。
この時、ゼニガメ is-a ポケモン なので 子 is-a 親、サブ is-a スーパーとなる。
ポケモン is-a ゼニガメとは言えない。

Class ゼニガメ {
頭
手
足
}
という関係になる。この時、頭はゼニガメの一部であるから、頭 part-ofゼニガメと言える。また、ゼニガメは頭を所有しているから、ゼニガメ has-a 頭と言える。